LLM Phone Assistant: Scaling AI in a Regulated Environment
Industry
Digital Banking
Client
Nubank
Focus Area
IVR System
Timeline
2023
Industry
Digital Banking
Client
Nubank
Focus Area
IVR System
Timeline
2023
1. Overview
When Nubank began exploring large language models for customer support, the opportunity was clear: automate high-volume interactions and reduce operational costs.
The risk was equally clear. In financial services, a single incorrect answer can compromise customer trust, trigger regulatory scrutiny, and generate reputational damage.
This case documents how we designed Nubank’s first LLM-powered phone assistant by prioritizing governability, predictability, and organizational alignment over short-term automation gains.
When Nubank began exploring large language models for customer support, the opportunity was clear: automate high-volume interactions and reduce operational costs.
The risk was equally clear. In financial services, a single incorrect answer can compromise customer trust, trigger regulatory scrutiny, and generate reputational damage.
This case documents how we designed Nubank’s first LLM-powered phone assistant by prioritizing governability, predictability, and organizational alignment over short-term automation gains.
When Nubank began exploring large language models for customer support, the opportunity was clear: automate high-volume interactions and reduce operational costs.
The risk was equally clear. In financial services, a single incorrect answer can compromise customer trust, trigger regulatory scrutiny, and generate reputational damage.
This case documents how we designed Nubank’s first LLM-powered phone assistant by prioritizing governability, predictability, and organizational alignment over short-term automation gains.
How do we introduce generative AI into financial support without compromising trust, reliability, or compliance?
2. Strategic Context
By 2023, Nubank’s phone channel handled millions of emotionally charged and financially sensitive calls each year. Traditional IVR systems were rigid, expensive, and increasingly ineffective for complex requests.
At the same time, generative AI adoption across the industry created internal pressure for rapid deployment and visible ROI. Early projections suggested that partial automation could unlock seven-figure annual savings. Several teams advocated for a highly autonomous model, optimized for coverage and speed. From a risk standpoint, this approach was fragile.
In phone interactions, customers are often stressed and time-constrained. Errors cannot be silently corrected. Failures are immediately visible. This context required a fundamentally different design approach.
By 2023, Nubank’s phone channel handled millions of emotionally charged and financially sensitive calls each year. Traditional IVR systems were rigid, expensive, and increasingly ineffective for complex requests.
At the same time, generative AI adoption across the industry created internal pressure for rapid deployment and visible ROI. Early projections suggested that partial automation could unlock seven-figure annual savings. Several teams advocated for a highly autonomous model, optimized for coverage and speed. From a risk standpoint, this approach was fragile.
In phone interactions, customers are often stressed and time-constrained. Errors cannot be silently corrected. Failures are immediately visible. This context required a fundamentally different design approach.
By 2023, Nubank’s phone channel handled millions of emotionally charged and financially sensitive calls each year. Traditional IVR systems were rigid, expensive, and increasingly ineffective for complex requests.
At the same time, generative AI adoption across the industry created internal pressure for rapid deployment and visible ROI. Early projections suggested that partial automation could unlock seven-figure annual savings. Several teams advocated for a highly autonomous model, optimized for coverage and speed. From a risk standpoint, this approach was fragile.
In phone interactions, customers are often stressed and time-constrained. Errors cannot be silently corrected. Failures are immediately visible. This context required a fundamentally different design approach.
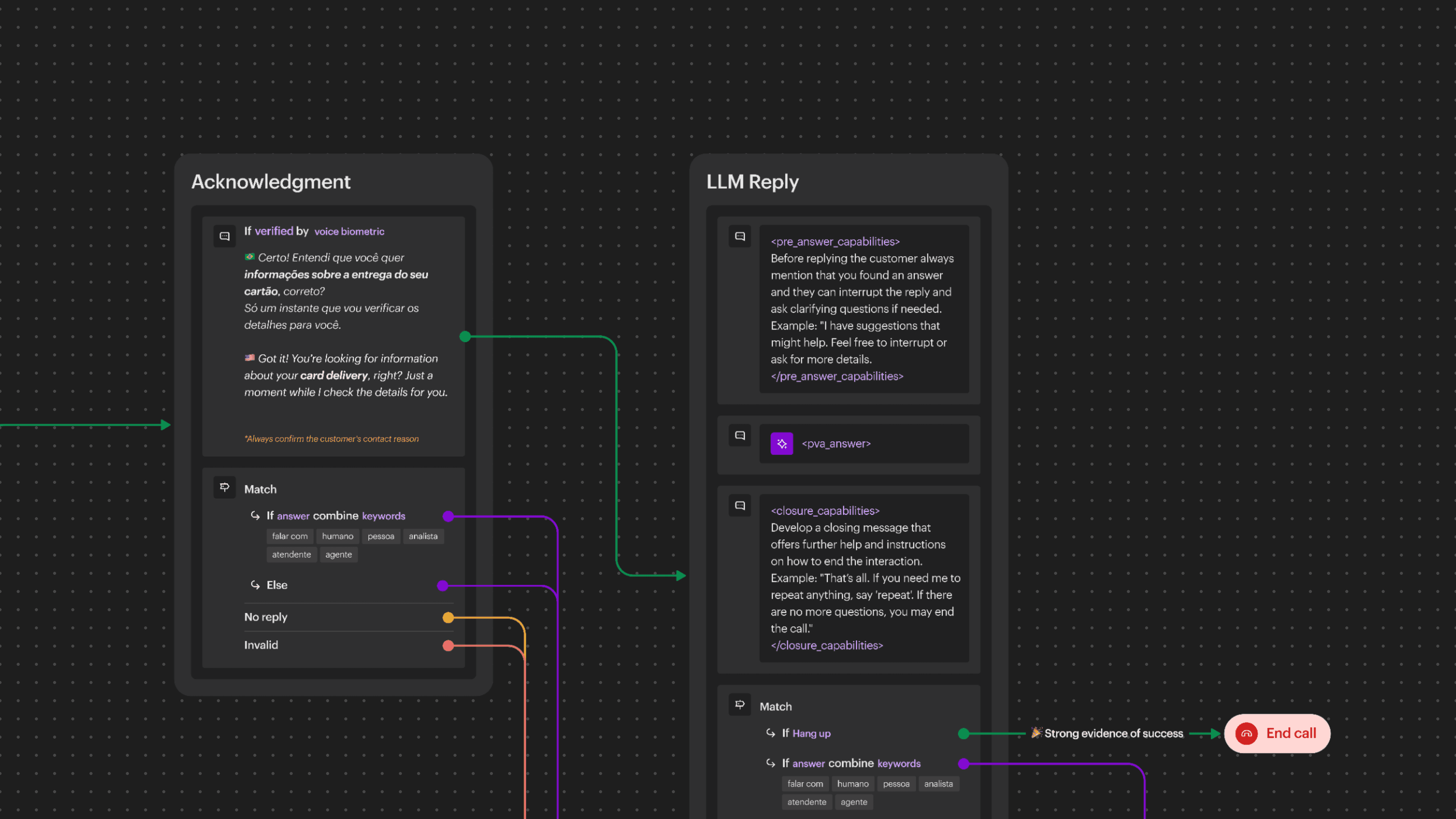
3. Role & Scope
Designing for reliability, not speed
As the only Product Designer at the time, my responsibility went far beyond interface design. My role often required moderating organizational momentum and reframing success around reliability rather than speed.
I was accountable for shaping how AI would behave, fail, and recover across the entire phone ecosystem:
Defining multimodal journeys across voice, chat, and app
Establishing interaction guardrails
Leading the experience layer of the Sierra.ai proof-of-concept
Aligning Product, Engineering, Data, Operations, and Legal
Creating reusable standards for future AI initiatives
Designing for reliability, not speed
As the only Product Designer at the time, my responsibility went far beyond interface design. My role often required moderating organizational momentum and reframing success around reliability rather than speed.
I was accountable for shaping how AI would behave, fail, and recover across the entire phone ecosystem:
Defining multimodal journeys across voice, chat, and app
Establishing interaction guardrails
Leading the experience layer of the Sierra.ai proof-of-concept
Aligning Product, Engineering, Data, Operations, and Legal
Creating reusable standards for future AI initiatives
Designing for reliability, not speed
As the only Product Designer at the time, my responsibility went far beyond interface design. My role often required moderating organizational momentum and reframing success around reliability rather than speed.
I was accountable for shaping how AI would behave, fail, and recover across the entire phone ecosystem:
Defining multimodal journeys across voice, chat, and app
Establishing interaction guardrails
Leading the experience layer of the Sierra.ai proof-of-concept
Aligning Product, Engineering, Data, Operations, and Legal
Creating reusable standards for future AI initiatives
"Felipe consistently took ownership beyond his formal scope, becoming a reference for strategic AI and conversation initiatives."
Product Sponsor
5. Trade-offs & Decisions
Autonomy vs Accountability
Early in the project, multiple stakeholders proposed treating the assistant as a largely autonomous reasoning system, relying on post-deployment monitoring to manage risk.
From a governance perspective, this was problematic. It assumed that errors could be corrected after reaching customers. I raised concerns that this approach would externalize risk to users and frontline agents. This position initially faced resistance. Some teams worried that stronger constraints would limit innovation and delay visible results.
We spent several weeks aligning on failure scenarios, regulatory exposure, and escalation costs before converging on a more conservative architecture.
The central shift was reframing success from “maximum automation” to “predictable resolution.”
Critical Trade-offs
We intentionally sacrificed short-term coverage in favor of long-term operational safety. Several high-risk intents were excluded from early automation despite business pressure.
Speed vs Reliability
Coverage vs Precision
Innovation vs Compliance
Missteps & Corrections
Early pilots assumed customers would adapt to long, multi-step voice instructions. Test data showed elevated abandonment and clarification loops. We had optimized for technical completeness rather than cognitive load.
Corrections included:
Shortening instructions
Redesigning confirmation flows
Introducing progressive disclosure
Adjusting pacing using call analytics
These changes reduced abandonment and improved first-contact resolution.
Autonomy vs Accountability
Early in the project, multiple stakeholders proposed treating the assistant as a largely autonomous reasoning system, relying on post-deployment monitoring to manage risk.
From a governance perspective, this was problematic. It assumed that errors could be corrected after reaching customers. I raised concerns that this approach would externalize risk to users and frontline agents. This position initially faced resistance. Some teams worried that stronger constraints would limit innovation and delay visible results.
We spent several weeks aligning on failure scenarios, regulatory exposure, and escalation costs before converging on a more conservative architecture.
The central shift was reframing success from “maximum automation” to “predictable resolution.”
Critical Trade-offs
We intentionally sacrificed short-term coverage in favor of long-term operational safety. Several high-risk intents were excluded from early automation despite business pressure.
Speed vs Reliability
Coverage vs Precision
Innovation vs Compliance
Missteps & Corrections
Early pilots assumed customers would adapt to long, multi-step voice instructions. Test data showed elevated abandonment and clarification loops. We had optimized for technical completeness rather than cognitive load.
Corrections included:
Shortening instructions
Redesigning confirmation flows
Introducing progressive disclosure
Adjusting pacing using call analytics
These changes reduced abandonment and improved first-contact resolution.
Autonomy vs Accountability
Early in the project, multiple stakeholders proposed treating the assistant as a largely autonomous reasoning system, relying on post-deployment monitoring to manage risk.
From a governance perspective, this was problematic. It assumed that errors could be corrected after reaching customers. I raised concerns that this approach would externalize risk to users and frontline agents. This position initially faced resistance. Some teams worried that stronger constraints would limit innovation and delay visible results.
We spent several weeks aligning on failure scenarios, regulatory exposure, and escalation costs before converging on a more conservative architecture.
The central shift was reframing success from “maximum automation” to “predictable resolution.”
Critical Trade-offs
We intentionally sacrificed short-term coverage in favor of long-term operational safety. Several high-risk intents were excluded from early automation despite business pressure.
Speed vs Reliability
Coverage vs Precision
Innovation vs Compliance
Missteps & Corrections
Early pilots assumed customers would adapt to long, multi-step voice instructions. Test data showed elevated abandonment and clarification loops. We had optimized for technical completeness rather than cognitive load.
Corrections included:
Shortening instructions
Redesigning confirmation flows
Introducing progressive disclosure
Adjusting pacing using call analytics
These changes reduced abandonment and improved first-contact resolution.


7. Experimentation
Learning without breaking trust
From the start, we adopted a phased experimentation strategy. No feature reached scale without passing through multiple layers of validation. We began with internal pilots, followed by shadow testing and limited public rollouts.
These experiments revealed critical friction points:
Customers struggled with long instructions
Background noise degraded recognition
Some intents were poorly suited for automation
Instead of optimizing superficially, we restructured the system around intent-focused flows with constrained autonomy.
We shifted from “What can the model answer?” to “What should the model be allowed to resolve?” This reframing significantly improved stability.
Governance model
As adoption grew, it became clear that AI success depended less on model quality and more on organizational alignment.
We formalized governance practices that included:
Centralized prompt management
Experience-level review cycles
Cross-functional approval flows
Shared quality benchmarks
Design became the connective tissue between technical capability and operational reality.
Learning without breaking trust
From the start, we adopted a phased experimentation strategy. No feature reached scale without passing through multiple layers of validation. We began with internal pilots, followed by shadow testing and limited public rollouts.
These experiments revealed critical friction points:
Customers struggled with long instructions
Background noise degraded recognition
Some intents were poorly suited for automation
Instead of optimizing superficially, we restructured the system around intent-focused flows with constrained autonomy.
We shifted from “What can the model answer?” to “What should the model be allowed to resolve?” This reframing significantly improved stability.
Governance model
As adoption grew, it became clear that AI success depended less on model quality and more on organizational alignment.
We formalized governance practices that included:
Centralized prompt management
Experience-level review cycles
Cross-functional approval flows
Shared quality benchmarks
Design became the connective tissue between technical capability and operational reality.
Learning without breaking trust
From the start, we adopted a phased experimentation strategy. No feature reached scale without passing through multiple layers of validation. We began with internal pilots, followed by shadow testing and limited public rollouts.
These experiments revealed critical friction points:
Customers struggled with long instructions
Background noise degraded recognition
Some intents were poorly suited for automation
Instead of optimizing superficially, we restructured the system around intent-focused flows with constrained autonomy.
We shifted from “What can the model answer?” to “What should the model be allowed to resolve?” This reframing significantly improved stability.
Governance model
As adoption grew, it became clear that AI success depended less on model quality and more on organizational alignment.
We formalized governance practices that included:
Centralized prompt management
Experience-level review cycles
Cross-functional approval flows
Shared quality benchmarks
Design became the connective tissue between technical capability and operational reality.
8. Impact
By the end of the initial rollout, the platform had become operational infrastructure.
It delivered measurable outcomes:
~20% self-service resolution rate
29-second reduction in average handling time
Projected US$970k in annual savings
Increased internal confidence in AI initiatives
More importantly, it established a scalable framework for responsible automation.
By the end of the initial rollout, the platform had become operational infrastructure.
It delivered measurable outcomes:
~20% self-service resolution rate
29-second reduction in average handling time
Projected US$970k in annual savings
Increased internal confidence in AI initiatives
More importantly, it established a scalable framework for responsible automation.
By the end of the initial rollout, the platform had become operational infrastructure.
It delivered measurable outcomes:
~20% self-service resolution rate
29-second reduction in average handling time
Projected US$970k in annual savings
Increased internal confidence in AI initiatives
More importantly, it established a scalable framework for responsible automation.